The one where I gather the data ….
The project is chosen, the proposal is written, now I just need some data to work with! Milestone 2 in the capstone course requires us to start constructing a detailed plan for how we are going to approach our project. For me, that means gathering all the data that I will need, and constructing a model in ModelBuilder to do the processing necessary to allow me to conduct the suitability analysis.
For those not familiar with GIS, let me explain what ‘suitability analysis’ actually means, and exactly how I intend to approach mine. A suitability analysis is essentially a way of asking “where is the best location for something?”. The “something” can be almost anything imaginable – a new business (ok, maybe not right now), habitat for some endangered species, even relocating an entire town. All that is required is a list of criteria for where your “something” should or shouldn’t be, and a representation of those data in GIS. My “something” is the landing site for a rover on Mars, and my criteria are a combination of engineering and science criteria, as described in the previous post. Each criterion that I want to inform the analysis will be represented as a raster. A raster is simply a grid of uniform cells where each cell holds a value representing some quantity – elevation data is an incredibly common example. Every time you take a photo with your smartphone or digital camera you are creating a raster image too (actually three raster bands stacked together, one each representing red, green, and blue – the combination of different intensities of those colours gives each cell (or pixel) a colour, and the combination of millions of such cells generates your image). For use in a suitability analysis, multiple rasters are typically reclassified to a common “good” to “bad” numeric scale, maybe 0 – 1 or 1 – 10. Don’t want to locate your dream house on a steep slope? Create a slope raster and assign high scores to low slope areas and low scores to high slope areas! Once you have reclassified all of your criteria, simply add the rasters together and the resulting areas with the highest scores are the most suitable locations for your “something”. Of course the process is rarely that simple, but that is the general idea.
For my landing site analysis I have obtained the following global datasets in raster form:
- elevation (from which I can generate a slope raster)
- albedo (i.e., surface reflectance)
- thermal inertia
- relative mineral abundance for hematite, carbonates, sulfates, and smectite clays
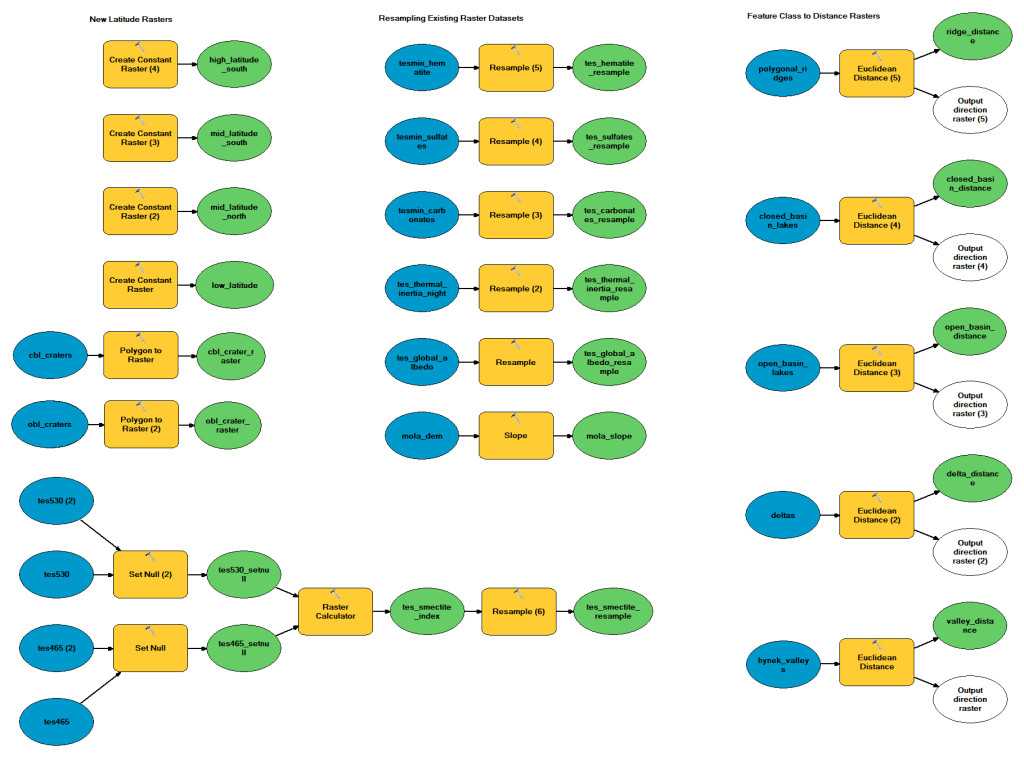
All of these rasters have different resolutions (i.e., the size of each cell is different for each dataset), ranging from approximately 460 m/pixel for the elevation data to nearly 15 km/pixel for the mineral abundance data. To facilitate comparison and allow the reclassified rasters to be added together, the low resolution datasets must be resampled and cells aligned with the highest resolution dataset. I also created constant rasters for different latitude bands, so that I could include a preference for lower latitudes over higher latitudes in my analysis.
There are also lots of Mars datasets that are not in raster form, but exist as vector, or feature, data (i.e., points, lines, or shapes). These datasets require a little more processing to be able to use them in a raster-based suitability analysis. For datasets such as the locations of water-carved channels or delta structures, my model creates distance rasters for these features, where the value in each cell is the distance to the nearest input feature (channel or delta structure). I also did some data processing to identify relatively large (> 25 km diameter) impact craters that are suspected of having hosted closed- or open-basin lakes at some point in the past. The locations of these craters will be converted directly to raster format (where each cell is either within or outwith such a crater). The final dataset of this type is the location of areas of ‘polygonal ridges’. These are landforms suspected, in many cases, of hosting mineral-filled veins and thus recording subsurface groundwater flow. A distance raster will be created for these features too.
The ModelBuilder model that accomplishes all of this data processing is shown below. The end result of running this model will be approximately 18 rasters. The second model that I will create will reclassify each of these rasters and add them together to create my final suitability raster. While that part sounds easy, the devil is, as always, in the detail. Exactly how I choose to reclassify the rasters, and the weight I give to different features, likely will have a significant impact on the final analysis. By automating the analysis in a model I can repeat it multiple times, giving different weight to different features, and assess this impact.